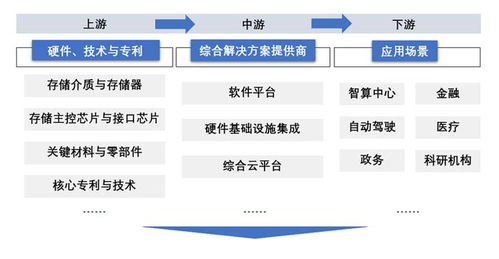
大型分布式網站架構技術總結 數據處理與存儲支持服務
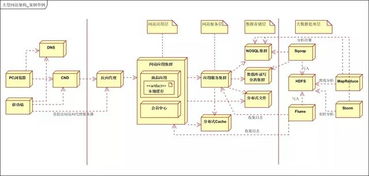
在當今互聯網高速發展的背景下,大型分布式網站已成為支撐海量用戶訪問和數據業務的核心基礎設施。數據處理與存儲支持服務作為分布式架構的關鍵組成部分,直接影響系統的性能、可靠性和擴展性。本文將從數據分片、存儲引擎、緩存策略、數據備份與恢復以及數據一致性等角度,系統總結大型分布式網站中數據處理與存儲支持服務的關鍵技術。
一、數據分片技術
數據分片(Sharding)是解決海量數據存儲和訪問性能問題的常用手段。通過將數據按特定規則(如哈希、范圍或列表)分布到多個數據庫節點,實現水平擴展。常見的分片策略包括:
1. 水平分片:按行拆分數據,適用于表數據量巨大的場景。
2. 垂直分片:按列拆分數據,適合表中字段多且訪問模式差異大的情況。
分片技術需考慮數據均勻分布、跨片查詢優化以及動態擴容等問題。
二、分布式存儲引擎
分布式存儲引擎負責數據的持久化與高效訪問。主流技術包括:
1. 分布式關系數據庫:如Google Spanner、TiDB,支持ACID事務和SQL接口,適用于強一致性要求的業務。
2. NoSQL數據庫:如Cassandra、HBase,適合高吞吐、弱一致性的場景,通過最終一致性模型提升可用性。
3. 對象存儲服務:如AWS S3、阿里云OSS,適用于非結構化數據的大規模存儲。
存儲引擎的選擇需結合數據模型、一致性需求及成本因素。
三、緩存策略
緩存是提升數據訪問性能的關鍵技術,通過將熱點數據存儲在內存中減少數據庫壓力。常用方案包括:
- 多級緩存:結合本地緩存(如Guava Cache)與分布式緩存(如Redis、Memcached),平衡延遲與一致性。
- 緩存更新策略:采用寫穿透(Write-Through)、寫回(Write-Back)或失效(Cache-Aside)機制,確保數據新鮮度。
- 緩存預熱與淘汰:通過LRU、LFU等算法管理內存資源,避免緩存擊穿和雪崩。
四、數據備份與恢復
為保證數據安全,分布式系統需具備完善的備份與恢復機制:
- 多副本存儲:通過跨機房、跨地域的數據冗余,提升容災能力。
- 增量備份與快照:定期備份增量數據,結合快照技術實現快速恢復。
- 一致性備份:利用分布式事務或日志同步(如WAL)確保備份數據的一致性。
五、數據一致性保障
在分布式環境中,數據一致性是核心挑戰。常用解決方案包括:
- 強一致性協議:如Paxos、Raft,通過多數派共識保證數據一致性,但可能犧牲部分性能。
- 最終一致性模型:通過沖突解決機制(如向量時鐘、CRDT)在可用性與一致性間取得平衡。
- 分布式事務:基于二階段提交(2PC)或TCC模式,支持跨服務數據操作。
大型分布式網站的數據處理與存儲支持服務需綜合運用分片、緩存、備份及一致性技術,構建高可用、高性能的數據架構。隨著云原生與AI技術的演進,智能調度、自動化運維及混合存儲模式將進一步推動分布式數據服務的創新與發展。
如若轉載,請注明出處:http://www.xlwbj.cn/product/36.html
更新時間:2026-01-06 10:10:41