AI數據存儲與流動的清晰圖解 數據處理與存儲支持服務詳解
在人工智能(AI)飛速發展的今天,數據作為其核心驅動力,其處理與存儲的流程直接影響著AI系統的效率與智能水平。理解數據從產生到最終被模型利用的全過程,是優化AI應用的關鍵。本文將提供一個清晰的圖解視角,系統闡述AI系統中的數據流動路徑,并深入解析支撐這一流程的底層數據處理與存儲支持服務。
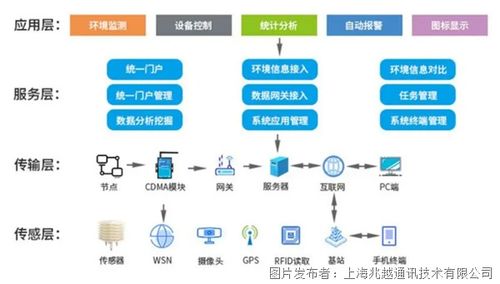
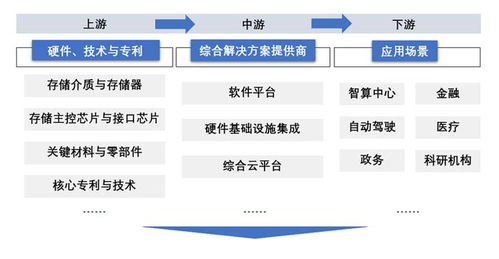
一、 AI數據流動全流程圖解
一個典型的AI數據生命周期可概括為以下核心環節,它們構成了一個持續迭代的閉環:
- 數據采集與注入:數據從各種源頭(如物聯網設備、業務數據庫、日志文件、公開數據集等)被收集。通過消息隊列(如Kafka)、數據同步工具或API接口,原始數據被實時或批量地“注入”到數據系統中。這是數據流的起點。
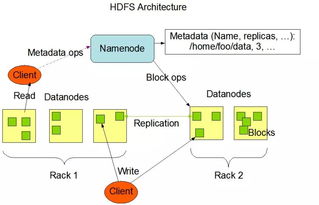
- 數據存儲與湖倉:采集到的原始數據首先被存入數據湖(如基于HDFS、S3的對象存儲),這是一個存儲所有原始格式數據的巨大倉庫。經過部分處理的數據可進入數據倉庫(如Snowflake、BigQuery),其結構更優化,便于商業智能分析。而專為AI設計的數據平臺則常采用 “湖倉一體” 架構,兼顧靈活性與高性能。
- 數據處理與加工:這是將原始數據轉化為AI可用“燃料”的核心階段。它包括:
- 數據清洗:去除錯誤、重復、不完整的臟數據。
- 數據標注:為監督學習任務,由人工或輔助工具為數據打上標簽。
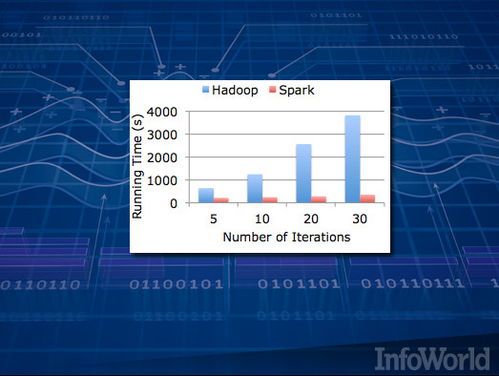
- 特征工程:通過轉換、組合、統計等方法,從原始數據中提取出對模型預測更有價值的特征。此過程通常在數據處理框架(如Spark、Flink)中完成。
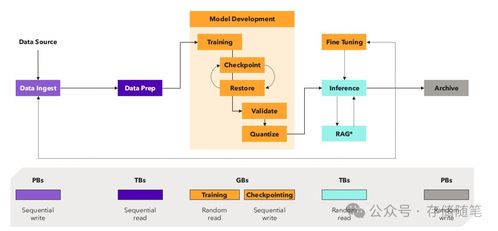
- 模型訓練與迭代:處理好的特征數據被送入模型訓練平臺(如TensorFlow, PyTorch集群)。訓練過程需要高速、低延遲地讀取海量數據,并對中間模型參數(檢查點)進行頻繁保存,這要求底層存儲具備極高的吞吐能力和并行訪問性能。
- 模型部署與推理:訓練好的模型被部署為在線服務。在推理階段,新的實時數據流入,模型進行計算并返回預測結果。這個過程要求極低的推理延遲,通常需要將模型和所需特征數據加載到高速緩存(如Redis)或內存數據庫中。
- 反饋與閉環:推理結果在實際應用中產生的效果數據(如用戶點擊、行為反饋)又被作為新的數據源采集回來,用于評估模型效果、發現數據漂移,并觸發新一輪的數據標注和模型再訓練,從而形成持續優化的閉環。
二、 關鍵的數據處理與存儲支持服務
為了保障上述數據流高效、穩定、安全地運轉,一系列支持服務至關重要:
- 高性能分布式存儲:
- 對象存儲:如AWS S3、阿里云OSS,提供海量、廉價、持久的原始數據存儲,是數據湖的基石。
- 文件存儲:如HDFS、GPFS,為大規模批處理作業提供高吞吐量的數據訪問。
- 塊存儲與云盤:為數據庫、高性能計算節點提供低延遲、高IOPS的存儲支持。
- 彈性計算與數據處理框架:
- 基于容器的服務(如Kubernetes)提供彈性的計算資源,根據數據處理任務動態伸縮。
- Spark、Flink等框架實現了大規模數據的并行處理和實時流計算。
- 特征存儲與管理:
- 專門的特征平臺(如Feast、Tecton)負責管理特征數據的定義、存儲、訪問和一致性,確保訓練和推理階段使用的是相同的特征,解決“訓練-服務偏斜”問題。
- 元數據與版本管理:
- 記錄數據集的來源、版本、血緣關系、質量指標(元數據),以及模型、特征的版本,保證實驗的可復現性和流程的可追溯性。MLflow、DVC等工具在此發揮作用。
- 數據安全與治理:
- 貫穿始終的服務,包括數據加密(靜態/傳輸中)、訪問控制、合規性檢查、數據脫敏和隱私保護技術(如差分隱私、聯邦學習),確保數據資產的安全合規使用。
三、
AI的數據流動并非簡單的線性傳輸,而是一個由采集、存儲、加工、消費、反饋構成的復雜閉環系統。現代AI基礎設施的核心目標,就是通過整合高性能存儲、彈性計算、智能數據管理以及全面的安全治理服務,將這個閉環打造得更加通暢、自動化和高效。清晰的架構圖解配合堅實的底層支持服務,是釋放數據價值、驅動AI持續進化的雙重保障。隨著AI對多模態、實時性要求的提升,存儲與數據處理服務的深度集成和智能化演進,將成為新的關鍵賽道。
如若轉載,請注明出處:http://www.xlwbj.cn/product/42.html
更新時間:2026-01-06 15:28:31